How to help make AI systems more international and inclusive with Google's Crowdsource App
I was taking a scooter ride in India with a friend of a friend about four years ago. We stopped for what he claimed was, and I disputed, the best roadside tea in Delhi. As we drank the tea, he expressed how he wanted to see more Indian culture represented within Google products. For example, he asked, why did it seem like most online searches for “bride” around the world show many photos of an ivory lace dress and gossamer veil, and fewer red Indian saris, mehendi tattoos and nose rings?
Over the years, as I talked to more and more people from South Asia, the Middle East, and Latin America, a recurring theme was that globally popular apps could offer more global user experiences. Another recurring theme was that there is a shared willingness to do something about this among users.
So I talked to the research teams at Google, and made it my mission to help Google partner with a globally diverse population in producing data and testing models.
A hands-on way to learn how training machine learning models works
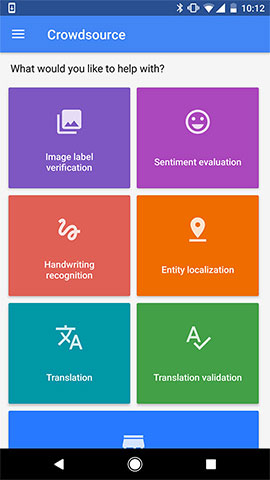
I work as the Product Manager of Crowdsource, a website and app which Google launched in 2016. Crowdsource empowers anyone, anywhere to help train Google’s own machine learning models directly. Machine Learning (ML) is a technique used to develop intelligent computing systems, or what’s known as artificial intelligence (AI). AI is the science of making machines “smarter,” helping them recognize vast patterns and help people solve challenges. ML works by getting computers to do something without specific programming. ML can help machines recognize patterns and adjust to unique situations, which helps build faster and more customized user experiences online or on mobile.
ML needs to be trained to recognize patterns. Crowdsource gives anyone the opportunity to play a role in the training process. You can label images, translate handwritten text in a variety of languages, and validate the sentiment of written sentences, which serve as the data that help to train ML models to recognize patterns.
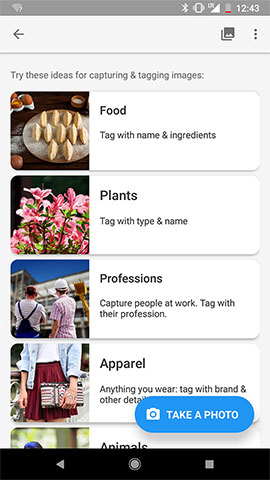
Recently, we also added options to our free app version of Crowdsource, so you can contribute images for data sets directly. You can choose to take and upload images that show daily objects from your world, helping co-create an open, global data set of images.
We also bring Crowdsource to communities in a variety of places, from Haiti to Ghana, across India and Latin America, and at events for U.S. students at HBCUs (historically Black colleges and universities) and HSIs (Hispanic-serving institutions), to demo it. These community-focused demos are intended to encourage people who want to learn more about machine learning to play an active role in building better ML models with Google, so that our products serve our users better by representing the diversity of the world. Their – and your – contributions directly influence all of our AI systems, which users experience when using apps such as Photos, Maps, and Translate.
In the last 2 years, the app has been downloaded half a million times. Users have collectively answered more than 400 million questions and verified more than 200 million image labels. Data gathered through the app is used across nearly all of Google’s AI products, from identifying images using Google Lens, to organizing pictures in Photos, to translating text from one language to another.
A big part of creating ML-based products is the collection and labeling of data. These labels aren’t seen by the end-users of the products, though. As a result, users may not immediately understand how a certain behavior of the ML-based product is a consequence of the data fed (or not fed) to the machine learning model. For example, if a bad restaurant review with a sarcastic “praise” of the service gets served to a reader as a positive review, users won’t be able to fully understand the cause of that error by the ML system.
Labeling a few sentences for “sentiment” gives users an idea of what kind of data machines train on. With this context, you can learn how a diverse set of inputs leads to better products for more people.
With tasks like “Image Capture,” users get to participate in the actual production of data. Crowdsource also features small tips to guide users, and we’re working on more explanations about how ML works into the app itself.
Elements of fun and community
Many of our early users let us know they wanted Crowdsource to be more like a game. We got feedback that users found it very relaxing to use the app during their commute or when taking a break between classes. There’s an element of fun to seeing different handwriting scribbles or a series of pictures of dogs, so our users always saw it as play. They asked for features like badges and points. And we’ve added some of these elements in response, with more to come.
A lot of the app’s features help users improve products for their communities, too, be it improving Translations or Language Understanding for Bengali language speakers, or improving Photos search for various breeds of dogs for people who love pets.
We’ve seen college students speak passionately to their peers about the app and even engage in some friendly competition. We’ve seen Crowdsource users from different parts of the world connect with each other over social media, and even fly long distances to hang out with each other after. The community is made up of partners who are excited and motivated to play an impactful role in building ML systems for everyone.
We’ve focused on fostering global communities that care about shared interests, from language, local culture, or a deep knowledge of birds or cars. These volunteers are our most passionate champions, and also sometimes our most vocal critics. Most of all, they’re all our partners in building inclusive AI.
Inspired by Anurag? Apply for a job at Google to create, code, design and build for everyone.



Contact Us
Stay in touch. We want to hear from you. Email us at Acceleratewithgoogle@google.com
Please note that this site and email address is not affiliated with any former Google program named Accelerator.