AI Outside In: Making data meaningless so AI can learn its meaning
To make information on Artificial Intelligence more useful and accessible to everyone, from students to non-technical people curious about how AI works, we’ve teamed up with Google’s People + AI Research (PAIR) initiative, whose mission is to make partnerships between people and AI more productive, engaging, and fair.
Here is the latest “AI Outside In” post by PAIR Writer in Residence, independent tech writer and blogger David Weinberger. He offers his outside perspective on key developments in AI research and will explain central concepts in the field of machine learning. He’ll be looking at the technology within a broader context of social issues and ideas. His opinions are his own and do not necessarily reflect those of Google.
Suppose you want a machine learning system to suggest paint names based on any color you specify. This has been done hilariously by Janelle Shane—“burf pink,” “navel tan”—but let’s say we want to do it more seriously (and without any reference to how Shane actually did it).
Machine learning (at least of the common sort called “supervised”) learns from the data you give it, so you first want to gather a large set of colors to which humans have applied various labels. You start by pulling in paint colors and their names from the on-line catalogs of all the paint suppliers you can find. Then you go to sites that suggest palettes of color with associated tags. You find some research that lists words that human subjects have freely associated with colors. You do this until, let’s say, you have fifty thousand colors and thousands of words linked to them.
Now you have your machine learning system see what it can discover about the relationships among the words and colors without any guidance from you. In this case, all the system will know is that the word “party” has been applied to 150 colors, most of which are pinkish, that “dusk” has been applied to 200 colors, most of which are subdued, “royal” has been applied to 300 colors that don’t seem to have a lot to do with one another, “happy” has never been applied to any shade of gray, and so forth.

Colors into Numbers
Of course that characterization wasn’t exactly accurate. Machine learning systems don’t know what colors or words are. All they know are numbers. The colors are easy to turn into numbers because they can be expressed as mixes of different quantifiable levels of red, green, and blue, as in the RGB standard that assigns each of those colors a number between 0 and 255. For example, a teal-ish swatch might be 66 parts red, 244 parts green, and 209 parts blue.
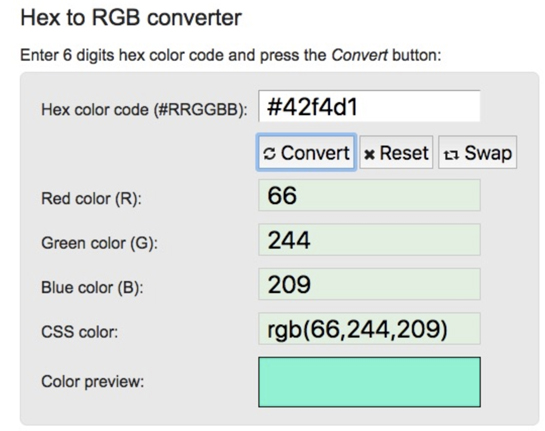
A utility for converting colors to their RGB values. Thanks, RapidTables!
But how do you assign numbers to words?
You don’t. You let the machine learning do it via a process called “embedding.” It is rather awesome.
How embedding works
First, you have to assign each unique word a reference number. The obvious way would be to start at 0 and hand them out in order. But, while machine learning systems do not know about words, they do know about numbers. They know, for instance, that 1 is closer to 2 than zero is. So, if you gave a system the sentence “Dogs chase squirrels,” and let it refer to “Dogs” as 0 and “squirrels” as 2, the system might think that “squirrels” is somehow more related to “chase” than to “Dogs,” which at best makes no sense. So you instead give each unique word a random number — random precisely so the machine learning system won’t learn anything interesting from it.
Now you’re going to set your machine learning loose on the colors and tags. It’s going to notice simple relationships among the colors and names, such as that the label “pink” seems to be applied to colors that have very high reds, very low greens, and fairly high blues. (RGB colors represent light, not paint, so they don’t mix the way we expect. Try them here.) The system may also notice that many colors with high blues, and greens that range from mid to high, create a sky blue color and have names that often include the words “sky,” “sunny,” “day,” and “above.” And it notes that “sunny” also shows up in colors that have very high reds and greens, because those two make yellow.
As the machine learning system notices those similarities, it assigns words new numbers that are not random. “Sky,” “sunny,” “day,” and “above” will be given numbers closer to one another. “Sunny” will also be close to the yellow-ish colors. How close depends on how often they’re used for similar colors. The closeness indicates the relationships discovered by the machine learning system.
The machine learning may go past simple color associations. It may notice that “pale” and “wash” are both used for lighter colors, no matter what the colors are. It may notice that “mediterranean,” “pastel,” and “summer” are often used when two of the constituent colors are high but the third one is in the middle. All of this can affect the number assigned to each word, for each bit of information can and should affect where the word stands in relation to all others.
Wondrous connections
In the language of computer science, each of these sorts of relationships — the relative strength of each of the three constituent hues, the sharing of labels, etc. — constitutes a “dimension,” and the words will each be given a number for each dimension, indicating their relationship to the other items in that dimension. A machine learning system might unearth thousands of dimensions — ways in which data are related — resulting in hundreds of different numbers being assigned to each word. For example, “summer” might be numerically close to yellow-ish colors when looking at hues, but might have a different number that brings it close to “pastel” in terms of color intensities.
Here’s a friendly video that graphically illustrates the “high dimensional space” embedding creates:

Having churned away discovering relationships among words and colors, words and words, and colors and colors, the system will now be ready for a user to input a color and get back the words the system is most confident are associated with that color, even if it’s a color the system has never seen. Or input a couple of words and it could perhaps make up a color it thinks represents them.
But the system can make these wondrous — and sometimes ridiculous — connections between meanings and colors only because it replaced meaningful words with meaningless numbers. Only then could the system find meanings that surprise us, amuse us, and may even feel exactly right.
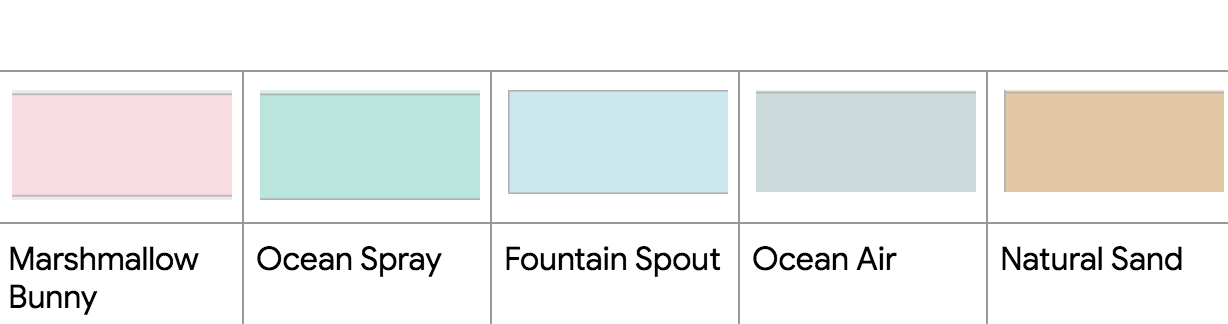
ANSWERS to my Benjamin Moore paint names exercise:
Hero illustration by Justin Gabbard.

This work is licensed under a Creative Commons Attribution 4.0 International License.


Contact Us
Stay in touch. We want to hear from you. Email us at Acceleratewithgoogle@google.com
Please note that this site and email address is not affiliated with any former Google program named Accelerator.